Google.com을 검색한다면?

- 1. Google.com 도메인에 일치하는 IP주소를 DNS 서버에서 검색
- 2. IP주소를 이용하여 웹 서버에게 html 문서를 요청
- 3. WAS와 DB에서 웹페이지 작업
- 4. 처리된 결과를 웹 서버가 클라이언트에게 html 문서로 전달
- 5. 브라우저가 렌더링되어 클라이언트에 출력 (Critical Rendering Path)
- 결론
이번 포스팅은 Google.com을 검색했을 때 일어나는 과정에 대해 알아보려한다.
1. Google.com 도메인에 일치하는 IP주소를 DNS 서버에서 검색
이전에 검색된(캐싱) DNS 기록이 있다면 바로 돌려주고, 그렇지 않다면 DNS 서버에 해당 도메인에 대한 요청을 한다.
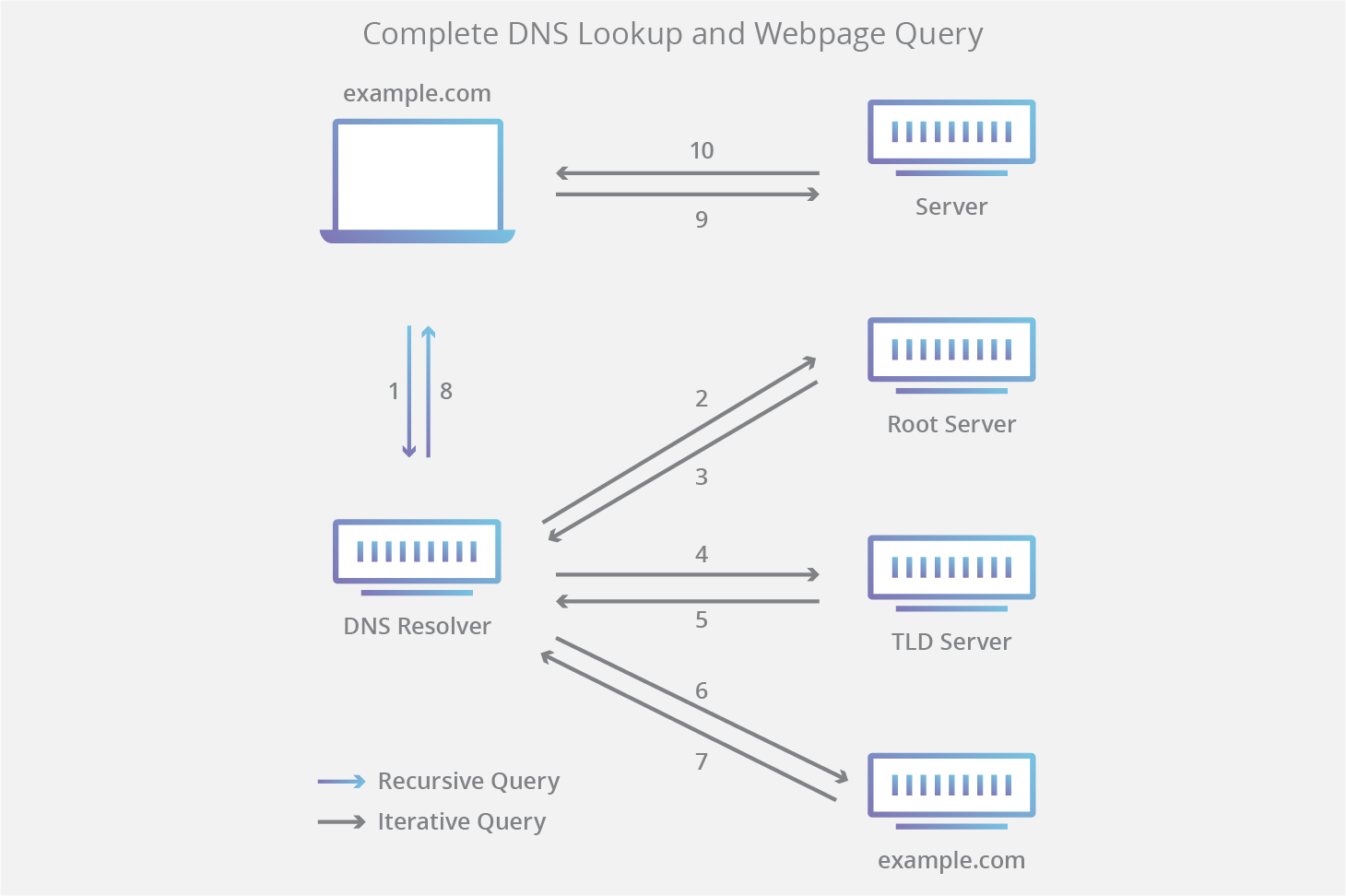
https://www.cloudflare.com/ko-kr/learning/dns/what-is-dns/
위의 과정처럼 DNS query를 재귀적으로 질의한다. Root -> TLD (Top Level Domain) -> 신뢰할 수 있는 도메인 순으로 이루어진다.
2. IP주소를 이용하여 웹 서버에게 html 문서를 요청
TCP/IP 프로토콜(4계층)로 서버와 연결을 한다. IP는 비신뢰성, 비연결성의 특징을 가지므로, 신뢰성과 연결성을 가지는 TCP와 함께 활용하여 통신한다.

3 way handshake 과정으로 연결을 맺어 데이터를 전송하고, 4 way handshake 과정을 마지막으로 연결이 종료된다.
3. WAS와 DB에서 웹페이지 작업
서버 하나가 모든 로직 및 데이터를 관리하면 부하가 생길 수 있으므로 WAS(Web Application Service)를 이용한다.
WAS란 장치에서 웹 어플리케이션을 수행하는 미들웨어이다.

클라이언트의 요청을 웹 서버는 정적인 페이지(HTML, CSS 등), WAS는 동적인 페이지(JS, jsp 등)를 생성하고, DB에서 필요한 데이터를 받아 만든다.
4. 처리된 결과를 웹 서버가 클라이언트에게 html 문서로 전달

이때, 적절한 HTTP Status 코드를 통해 서버에서 돌려준 결과의 상태를 표시한다
5. 브라우저가 렌더링되어 클라이언트에 출력 (Critical Rendering Path)

HTML은 해석하여 태그에 따라 DOM Tree로, CSS도 유사하게 CSSOM Tree로 변경하여 최종적으로 Render Tree를 생성한다.
이후 각 요소(트리의 노드)에 대한 Layout을 잡고 실제로 클라이언트 화면에 출력한다.
결론
코드만 주구장창 두들겨 내부적인 동작은 잘 모른채 지나왔다. 이렇게 한번 정리하고나니 작성했던 코드들의 사용 이유가 하나씩 이해가 된다.
지금까지도 그리고 앞으로도 사용하는 기술에 대해 최소한의 동작을 이해하고 넘어가야 새로운 기술을 위한 발판이 될 수 있다는 것을 새삼 느낀다😭